This is an article from the Shaped 1.0 documentation. The APIs have changed and information may be outdated. Go to Shaped 2.0 docs
Enriching Movie Descriptions with LLMs
In this tutorial, we'll show you how to use Shaped Transforms to enrich a dataset with powerful, generated content. For this scenario, we'll take a simple table of movies and use a Large Language Model (LLM) to create clean, consistent, and engaging fatures—perfect for powering search and recommendations use-cases.
The best part? We'll be doing all of this directly from the Shaped dashboard, with no coding required.
Let's get started! 🚀
1. Sign-Up to Shaped
First, let's get you set up with a Shaped account.
- Navigate to the Shaped website and sign up for a free trial. You'll be asked to provide some basic information to create your organization.
- Once you've signed up, you'll land on the home page of your new Shaped organization. This is your mission control for creating datasets, building models, and managing transforms.
2. Getting the Dataset
For this tutorial, we'll use the classic MovieLens dataset. We'll use the "latest small" version, which is perfect for a quick demo.
- Download the dataset directly from this link: ml-latest-small.zip.
- Unzip the file. Inside, you'll find several files. The one we care about for this tutorial is
movies.csv.
This file contains a movieId, title, and a pipe-separated list of genres for thousands of movies. We'll use the title and genres as the input for our enrichment.
3. Uploading the Dataset to Shaped
Next, let's upload movies.csv to create our first dataset in Shaped.
- From the home page, navigate to the Connectors tab on the left-hand navigation bar.
- Click the Create Connector button and select the File Upload option.
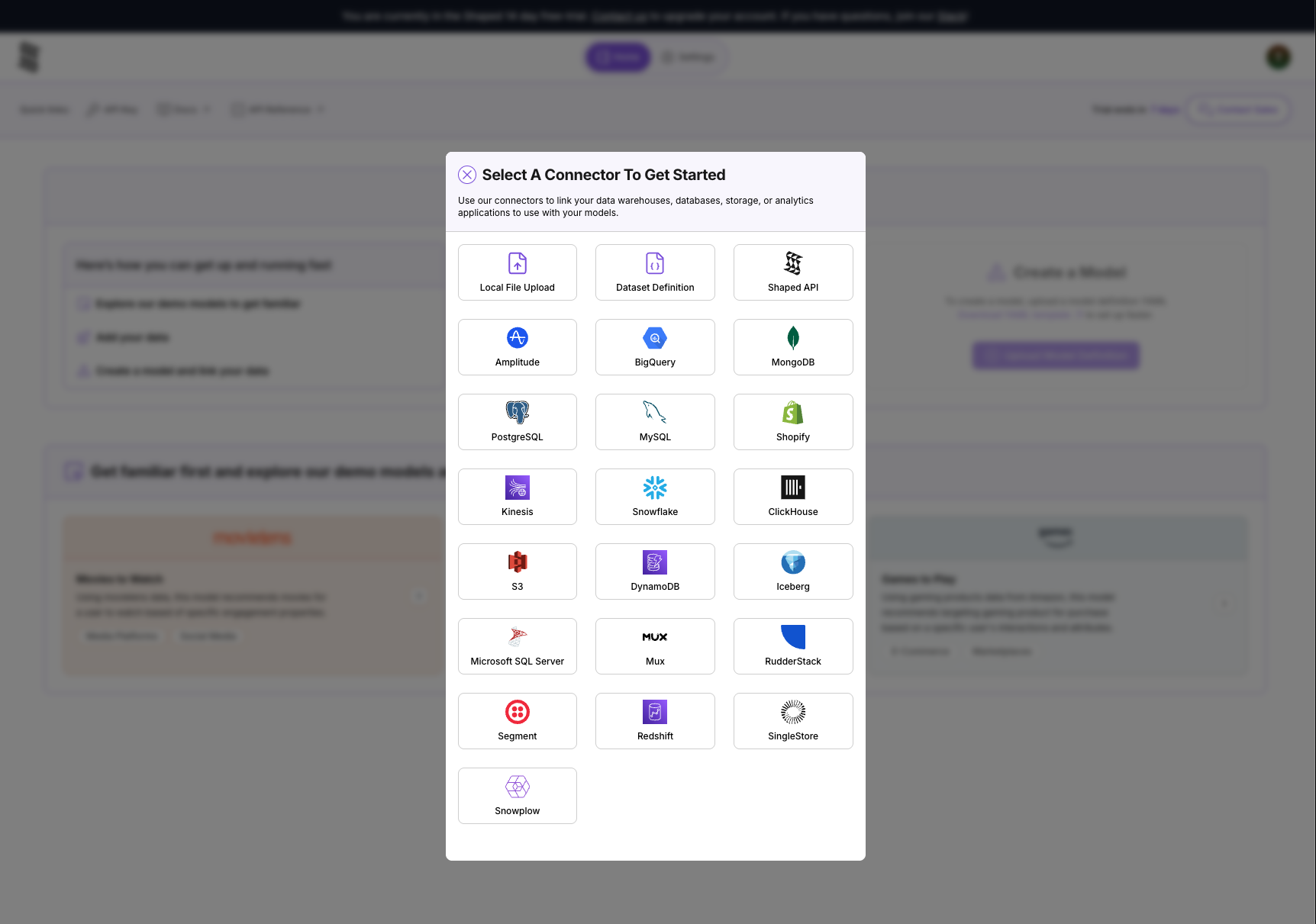
- Drag and drop the
movies.csvfile directly into the upload area. Shaped will automatically infer the schema and create a new dataset from the file.
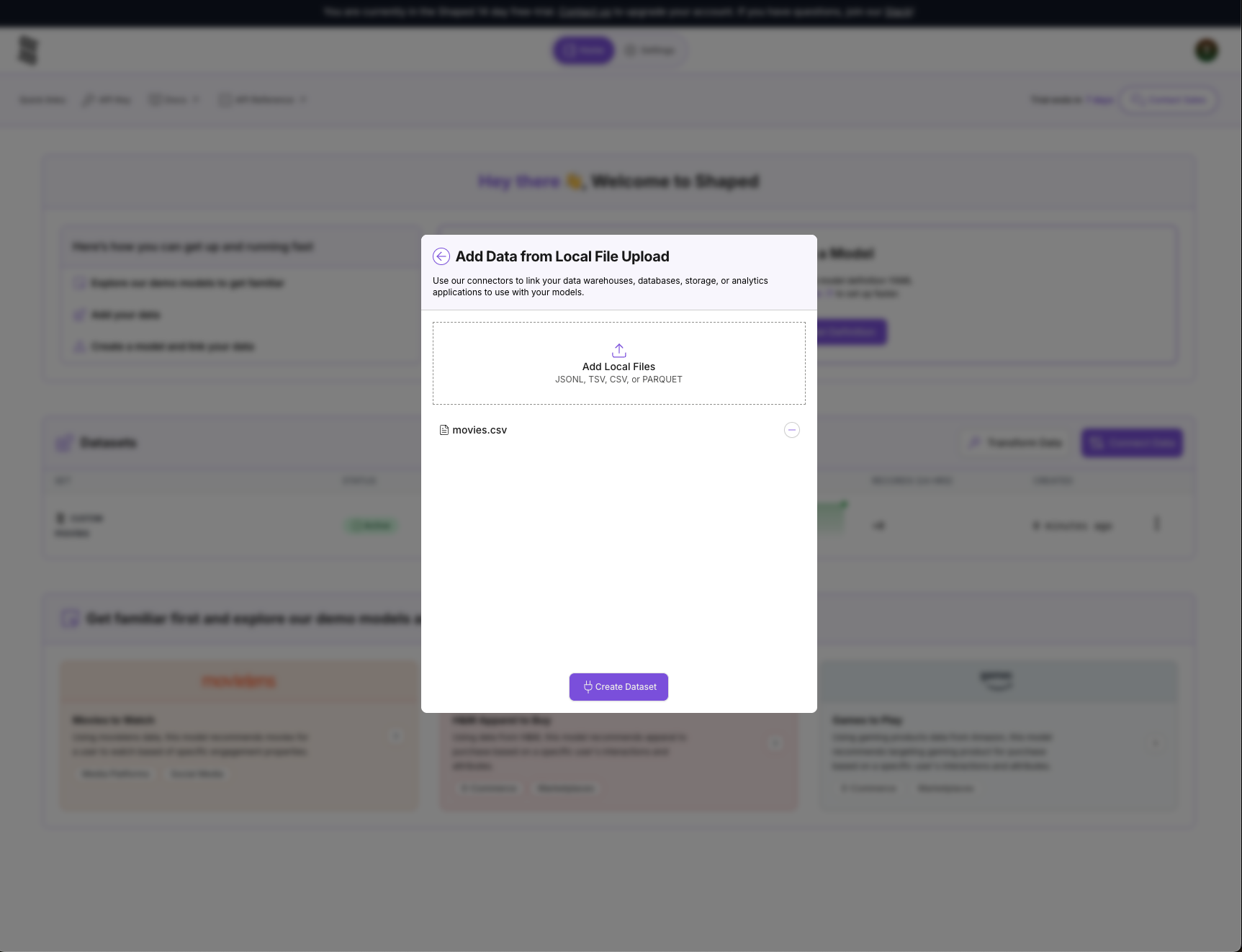
- Once the upload is complete, you'll see a confirmation that your new dataset,
movies, has been created. Click on the dataset name to view it.
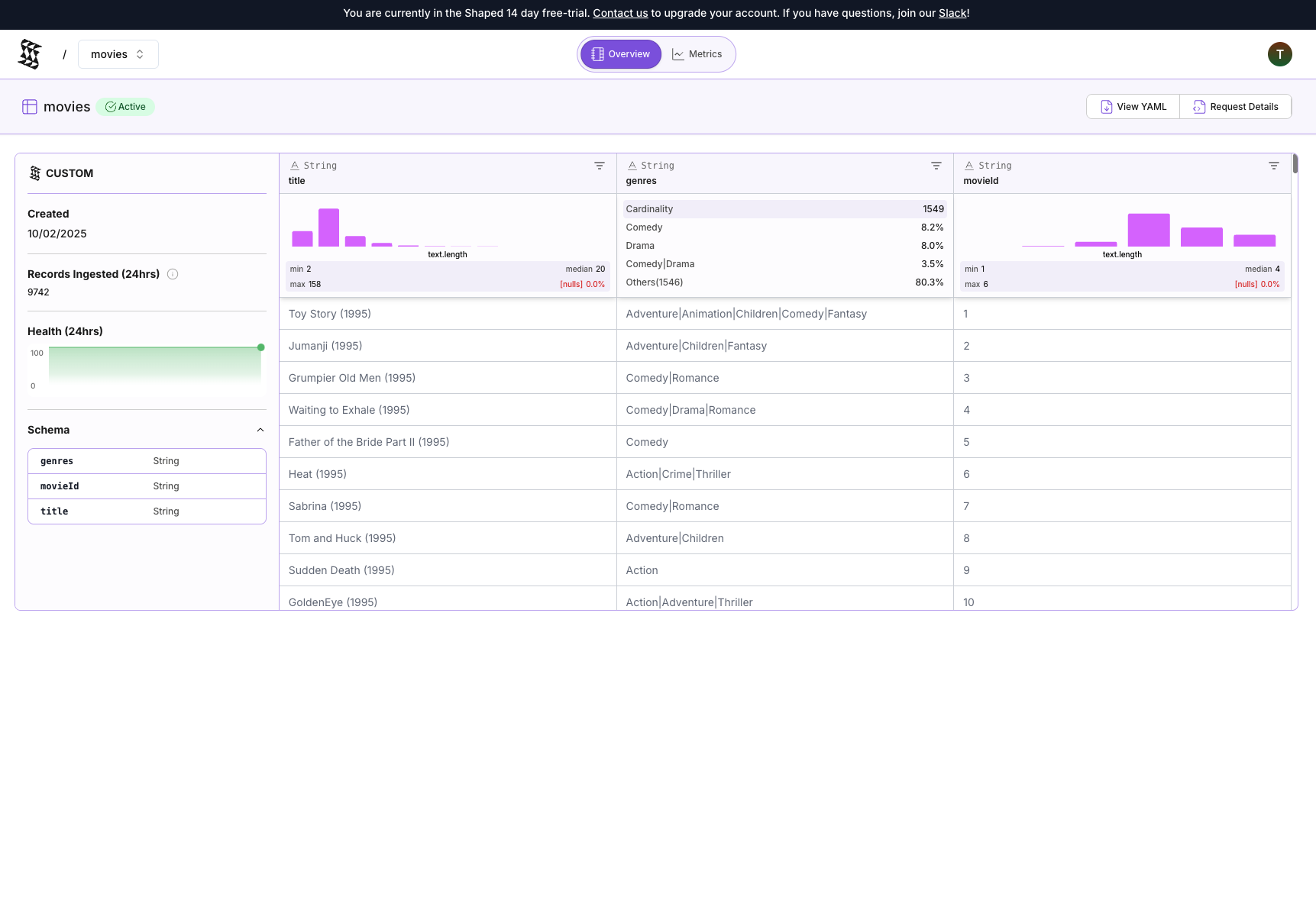
- You can now see your data inside Shaped! Notice the
titleandgenrescolumns. This is the raw information we are going to enrich.
4. Creating the LLM Enrichment Transform
Now for the exciting part! We'll create a Transform that reads from our movies dataset, uses an LLM to generate a description for each movie, and saves the result to a new, enriched table.
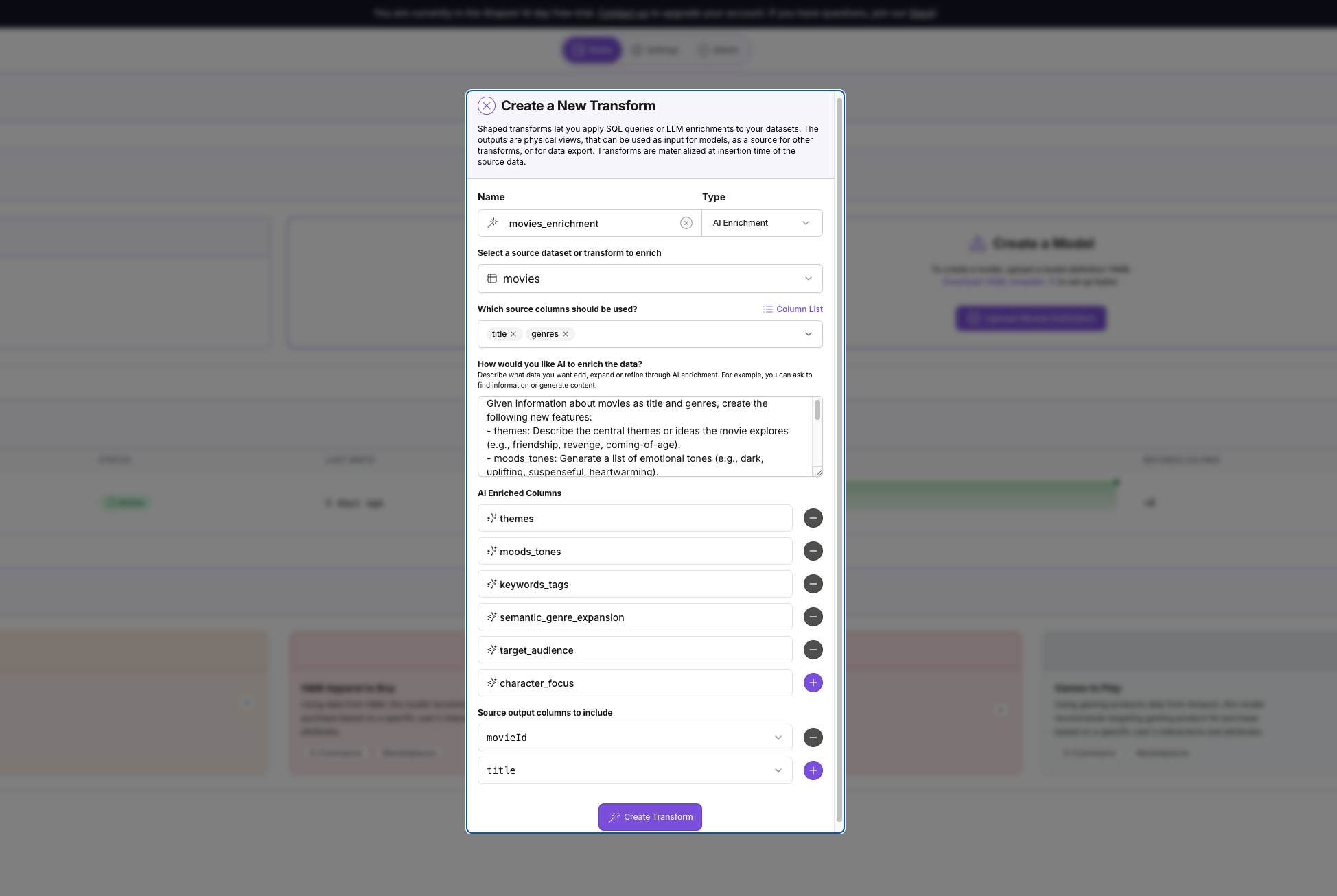
- Navigate to the Transforms tab on the left-hand navigation bar and click Create Transform.
- In the creation form:
-
Give your transform a name, like
movies_enrichment. -
For the Type, select AI Enrichment.
-
For the Source dataset, select the
moviesdataset we just uploaded. -
For the Source columns, select
titleandgenres. -
For the prompt, paste the following:
Given information about movies as title and genres, create the following new features:
- themes: Describe the central themes or ideas the movie explores (e.g., friendship, revenge, coming-of-age).
- mood_tones: Generate a list of emotional tones (e.g., dark, uplifting, suspenseful, heartwarming).
- keyword_tags: Create a set of descriptive tags that capture the movie's setting, mood, and subject matter.
- semantic_genre_expansion: Expand the basic genres into a richer natural-language description (e.g., "A lighthearted romantic comedy about second chances").
- target_audience: Predict the ideal audience segment (e.g., families, teenagers, adults, animation fans).
- character_focus: Identify the likely character focus or archetypes (e.g., "a brave child protagonist," "an unlikely hero," "ensemble cast"). -
For the AI Enriched Columns, select
themes,mood_tones,keyword_tags,semantic_genre_expansion,target_audience, andcharacter_focus. -
For the Source Output Columns to include, select
movie_idandtitle.
-
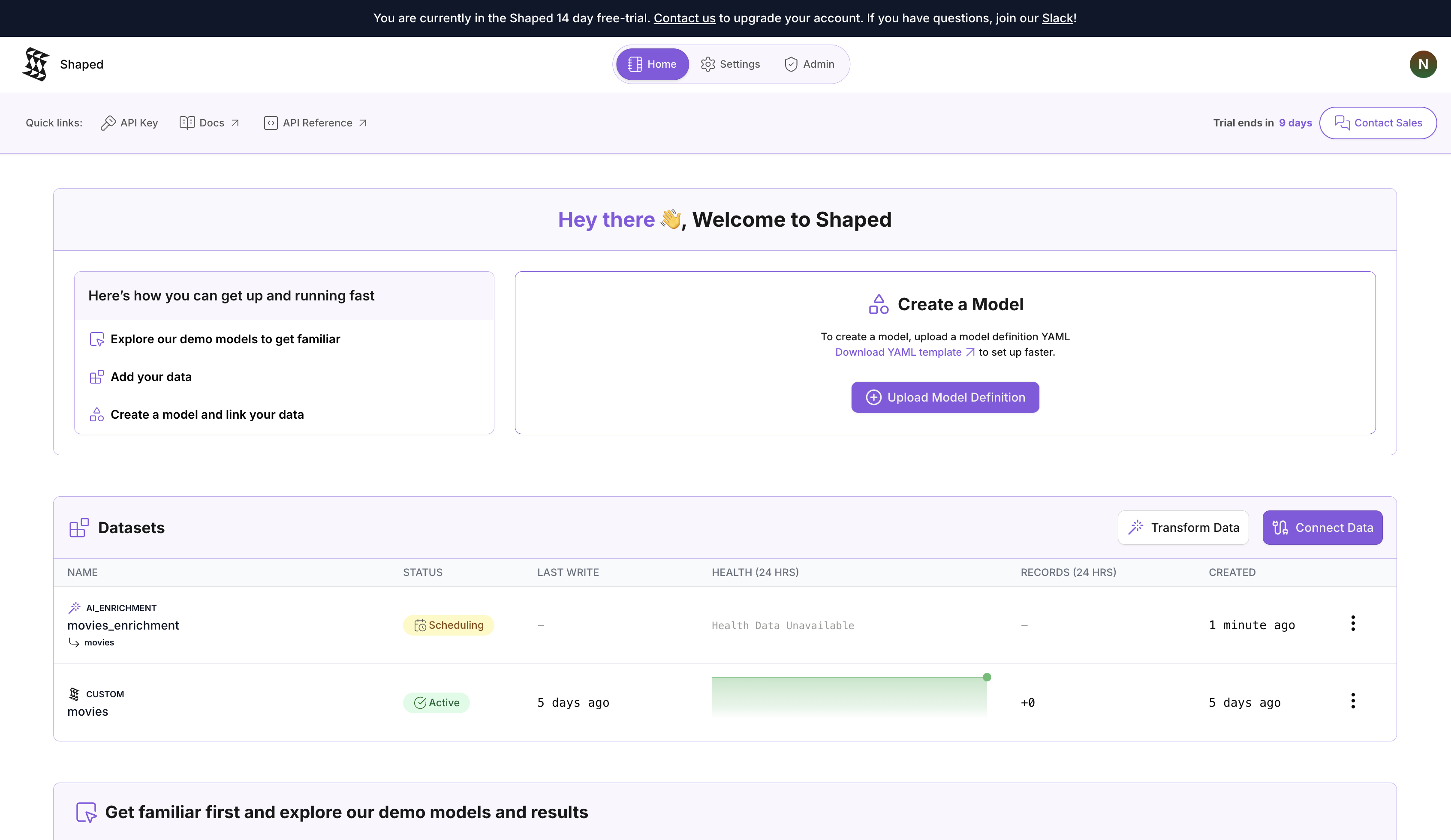
- Click Create Transform. Shaped will immediately start the backfilling process. This means it's iterating through every row in your
movies_csvdataset and running the AI enrichment you just defined.
5. Evaluating Results & Exporting
Once the backfill process is complete, you can view your newly enriched dataset.
- The status of the transform will change to Finalized. Click on the transform to see its output.
- You'll now see your original movie data, plus the new
themes,mood_tones,keyword_tags,semantic_genre_expansion,target_audienceandcharacter_focuscolumns filled with high-quality, consistent descriptions generated by the LLM!
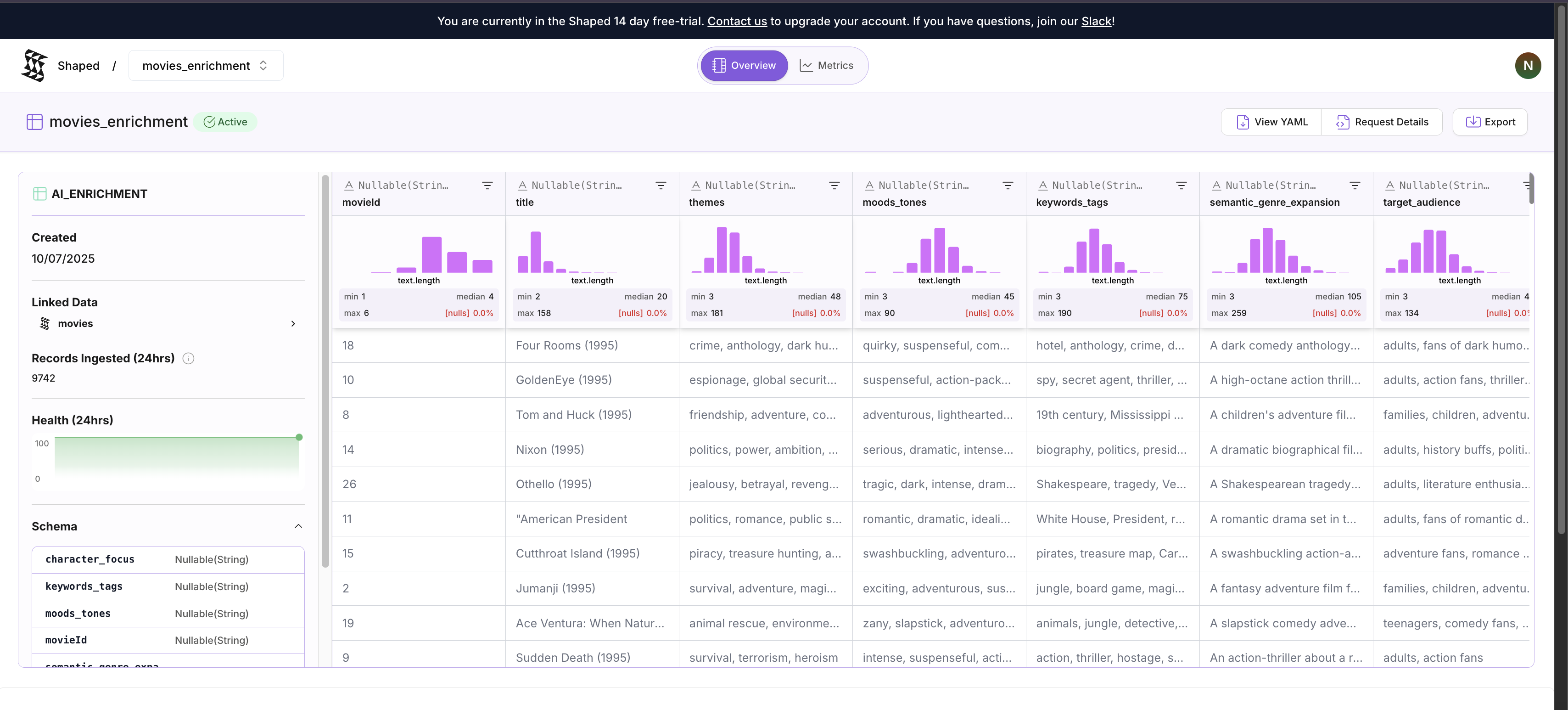
Before:
- Title: Toy Story (1995)
- Genres: Adventure|Animation|Children|Comedy|Fantasy
After:
- themes: "friendship, loyalty, dealing with change, jealousy, acceptance"
- mood_tones: "comedic, adventurous, heartwarming, nostalgic, whimsical"
- keyword_tags: "toys, childhood, friendship, adventure, animated, comedy, fantasy, 1990s"
- semantic_genre_expansion: "A comedic animated fantasy adventure about toys that come to life, exploring themes of friendship and jealousy."
- target_audience: "families, children, animation fans, adults nostalgic for the 90s"
- character_focus: "an unlikely hero (Woody), a new friend (Buzz Lightyear), ensemble cast of toys"
This enriched data is now ready to be used to power a semantic search index or as rich features for a recommendation model. You can easily export this data by clicking the Export button to use it in other systems.
6. Cleaning Up
To keep your Shaped organization tidy, you can clean up the resources we created for this tutorial.
- Navigate to the Transforms tab and delete the
movies_enrichmenttransform. - Navigate to the Datasets tab and delete the
moviesdataset.
And that's it! You've successfully used Shaped's no-code Content Enrichment to transform a simple CSV into a feature-rich dataset ready for modern AI applications.