This is an article from the Shaped 1.0 documentation. The APIs have changed and information may be outdated. Go to Shaped 2.0 docs
Book Recommendations (Goodbooks)
In this tutorial we'll show you how to setup a model for the Goodbooks-10k dataset. This dataset contains 6 million ratings for 10k most popular books from a site similar to goodreads. With Shaped we'll be able to create a book recommendation model that can predict the books each reader the most likely want to read.
This tutorial will be shown using Shaped's MongoDB data connector but you can easily translate to any of the data stores we support.
Let's get started! 🚀
You can follow along in our accompanying notebook!
Using Shaped
Setup
- Install
shapedto leverage the Shaped CLI to create, view, and use your model. - Install
pyyamlto create Model schema files.
! pip install shaped
! pip install pyyaml
Initialize the Client
Replace <YOUR_API_KEY> with your API key below.
If you don't have an API Key, feel free to signup on our website :)
import os
SHAPED_API_KEY = os.getenv('TEST_SHAPED_API_KEY', '<YOUR_API_KEY>')
Initialize the Shaped CLI with your API key.
! shaped init --api-key $SHAPED_API_KEY
Dataset Preparation
Setup
Install pandas to view and edit the sample dataset.
! pip install pandas
Download public dataset
Fetch the publicly hosted Goodbooks dataset.
import zipfile
import os
def download_and_extract_dataset(url, destination_directory):
print(f"Downloading dataset from {url}...")
os.makedirs(destination_directory, exist_ok=True)
zip_file_path = os.path.join(destination_directory, os.path.basename(url))
# Download the ZIP file
!wget $url --no-check-certificate -P $destination_directory
# Extract the contents of the ZIP file
with zipfile.ZipFile(zip_file_path, 'r') as zip_ref:
zip_ref.extractall(destination_directory)
# Directory name for storing datasets
DIR_NAME = "notebook_assets"
# Download and extract each dataset
datasets = [
("https://github.com/zygmuntz/goodbooks-10k/releases/download/v1.0/ratings.zip", DIR_NAME),
("https://github.com/zygmuntz/goodbooks-10k/releases/download/v1.0/books.zip", DIR_NAME)
]
for dataset_url, destination_dir in datasets:
download_and_extract_dataset(dataset_url, destination_dir)
Let's take a look at the downloaded dataset. There are two tables of interest:
bookswhich are stored inbooks.csvratingswhich are stored inratings.csv
import pandas as pd
data_dir = "notebook_assets"
events_df = pd.read_csv(f'{data_dir}/ratings.csv')
books_df = pd.read_csv(f'{data_dir}/books.csv')
display(events_df.head())
display(books_df.head())
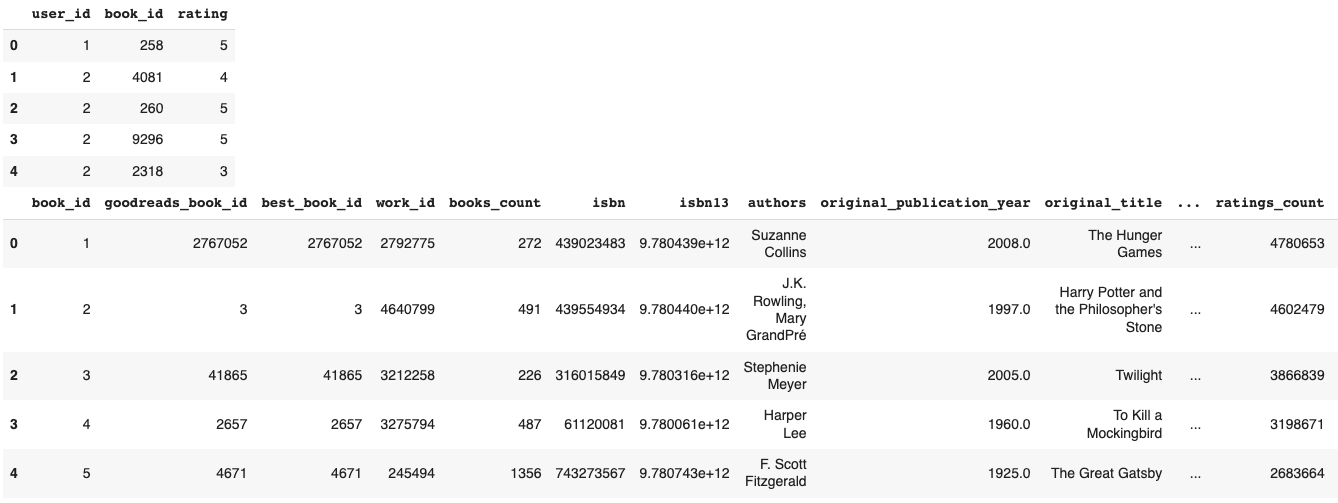
In most cases, you'd have to spend time cleaning all this data, however, with Shaped you can feed it through in this state and Shaped will do the cleaning for you. The way we do this is by treating all input data as unstructured, and using large language models to distill the meaning of each column.
Shaped doesn't require much data to work. At a minimum we need to know the user_id, item_id, label, and created_at columns of the interactions table. If the users and items tables are provided then the only requirement is their respective id columns are aliased to user_id and item_id.
To keep things simple, in this tutorial we will focus on the interaction data only (i.e., events_df). All 3 existing columns are relevant:
user_id: Is the reader who is rating the book. The ID value is contiguous, which ranges from 1 to 53424.book_id: Is a unique identification for a book. The ID value is contiguous, which ranges from 1 to 10000. It will be used as an item to train our models.ratings: Is the rating of a book given by a reader, which ranges from 1 to 5.
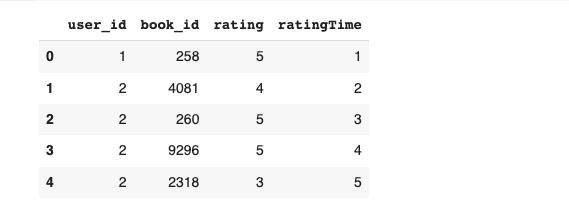
Besides the above 3 columns, shaped also requires the interaction data to have created_at column, which is missing from the given data. As specified in the docs, the ratings are already sorted by time, so we can manually create an extra ratingTime column to reflect that property.
events_df = events_df[["user_id","book_id","rating"]]
events_df = events_df.head(1000)
# Create a new column 'ratingTime' with ascending values
events_df['ratingTime'] = range(1, len(events_df) + 1)
display(events_df.head())
modified events:
Create and Insert Shaped Dataset Through MongoDB Connector
Shaped has support for many data connectors! For this tutorial we're going to be using the MongoDB connector to upload the local data from csv files to Shaped. To do that we need to:
- Set up a MongoDB instance on your own. Make sure you also obtain your connection string (way to find it) and create both database and collection so we can make reference to them in the schema in step 2.
- Create a
.yamlfile containing the dataset schema definition, and fill in the MongoDB instance's configuration detail (i.e., connection string, the names of the database and collection you created). In this tutorial, we named database as "goodbooks" and collection as "ratings". - Use Shaped CLI to create the dataset with the schema defined in the
.yamlfile. - Use Shaped CLI to insert or upload the local
.csvfiles into the shaped dataset we've just created through the MongoDB connector.
Once you finish step 1, we need to create a Shaped dataset. To do that, we first need to create a dataset definition which includes the schema as follows:
"""
Create a Shaped Dataset schema for each of the datasets and store in a .yaml file.
"""
import yaml
dir_path = "notebook_assets"
events_dataset_schema = {
"name": "goodbooks_events",
"schema_type": "MONGODB",
"schedule_interval": "@daily",
"mongodb_connection_string": "<YOUR_CONNECTION_STRING>",
"database": "goodbooks",
"collection": "ratings"
}
with open(f'{dir_path}/events_dataset_schema.yaml', 'w') as file:
yaml.dump(events_dataset_schema, file)
You can then use this definition to create the goodbooks_events dataset with the create-dataset command using Shaped's CLI:
! shaped create-dataset --file $DIR_NAME/events_dataset_schema.yaml
We can take a look of the dataset status using list-datasets.
! shaped list-datasets
Response:
datasets:
- dataset_name: goodbooks_events dataset_uri: https://api.prod.shaped.ai/v1/datasets/goodbooks_events created_at: 2023-09-08T12:35:12 UTC schema_type: MONGODB status: ACTIVE
The dataset is active, which means we are ready to insert the actual local csv data into it through dataset-insert command.
! shaped dataset-insert --dataset-name goodbooks_events --file $DIR_NAME/ratings.csv --type 'csv'
Model Creation
We're now ready to create your Shaped model! To keep things simple, today, we're using the Goodbooks rating data to build a collaborative filtering model. Shaped will use these ratings to determine which reader like which book with the assumption that the higher the rating the more likely a reader will want to read that book.
Here's the create model definition we'll be using.
"""
Create a Shaped Model schema and store in a .yaml file.
"""
import yaml
goodbooks_ratings_model_schema = {
"model": {
"name": "goodbooks_book_recommendations"
},
"connectors": [
{
"type": "Dataset",
"id": "goodbooks_events",
"name": "goodbooks_events"
}
],
"fetch": {
"events": "SELECT JSON_EXTRACT_STRING(document, '$.book_id') as item_id, JSON_EXTRACT_STRING(document, '$.rating') as label, JSON_EXTRACT_STRING(document, '$.ratingTime') as created_at, JSON_EXTRACT_STRING(document, '$.user_id') as user_id FROM goodbooks_events"
}
}
dir_path = "notebook_assets"
with open(f'{dir_path}/goodbooks_ratings_model_schema.yaml', 'w') as file:
yaml.dump(goodbooks_ratings_model_schema, file)
Next, let's use the create-model command to create the model!
"""
Create a Shaped Model using the .yaml schema file.
"""
! shaped create-model --file $DIR_NAME/goodbooks_ratings_model_schema.yaml
{
"connectors": [
{
"id": "goodbooks_events",
"name": "goodbooks_events",
"type": "Dataset"
}
],
"fetch": {
"events": "SELECT JSON_EXTRACT_STRING(document, '$.book_id') as item_id, JSON_EXTRACT_STRING(document, '$.rating') as label, JSON_EXTRACT_STRING(document, '$.ratingTime') as created_at, JSON_EXTRACT_STRING(document, '$.user_id') as user_id FROM goodbooks_events"
},
"model": {
"name": "goodbooks_book_recommendations"
}
}
model_url: https://api.prod.shaped.ai/v1/models/goodbooks_book_recommendations
Your recommendation model can take up to a few hours to provision your infrastructure and train on your historic events. This time mostly depends on how large your dataset is i.e. the volume of your users, items and interactions and the number of attributes you're providing. For the model you just created it will take no more than 30 minutes.
While the model is being setup, you can view its status with either the List Models or View Model endpoints. For example, with the CLI shaped list-models you can inspect the status of created models, going through the following stages in order:
SCHEDULINGFETCHINGTRAININGDEPLOYINGACTIVE
! shaped list-models
Response:
models:
- model_name: goodbooks_book_recommendations model_uri: https://api.prod.shaped.ai/v1/models/goodbooks_book_recommendations created_at: 2023-09-12T01:46:21 UTC status: SCHEDULING
You can periodically poll Shaped to inspect these status changes. Once it's in the ACTIVE state, you can move to next step and use it to make rank requests!
Rank!
You're now ready to fetch your Goodbooks book recommendations! You can do this with the Rank endpoint. Just provide the user_id you wish to get the recommendations for and the number of recommendations you want returned. Make sure the user_id indeed exists in the dataset.
Shaped's CLI provides a convenience rank command to quickly retrieve results from the command line. You can use it as follows:
! shaped rank --model-name goodbooks_book_recommendations --user-id 5 --limit 5
Response:
ids:
- '8'
- '27'
- '101'
- '24'
- '2' scores:
- 1.0
- 0.90909091
- 0.90909091
- 0.90909091
- 0.81818182
The response returns 2 parallel arrays containing the book ids and ranking scores for the books that Shaped estimates are most relevant to the given reader.
If you want to integrate this endpoint into your website or application you can use the Rank POST REST endpoint directly with the following request:
! curl https://api.prod.shaped.ai/v1/models/goodbooks_book_recommendations/rank \
-H "x-api-key: <YOUR_API_KEY>" \
-H "Content-Type: application/json" \
-d '{ "user_id": "5", "limit": 5 }'
Congrats! You just retrieved the top 5 most liked books for the user with id 5! 🍾. Now let's add ranking to your product :)
Clean Up
Don't forget to delete your created shaped datasets, models and associated notebook assets once you're finished with them. You can do it with the following CLI command:
! shaped delete-dataset --dataset-name goodbooks_events
! shaped delete-model --model-name goodbooks_book_recommendations
! rm -r notebook_assets
Response:
message: Dataset with name 'goodbooks_events' was successfully deleted
message: Model with name 'goodbooks_book_recommendations' is deleting...