This is an article from the Shaped 1.0 documentation. The APIs have changed and information may be outdated. Go to Shaped 2.0 docs
Overview
Shaped provides as a declarative interface for defining your recommendation & search models. Within the definition you define:
- The data you want to use to train your ranking model
- Your objective function e.g. clicks, add-to-cart, etc.
- Any customization you want to make to the ranking model. For example, you can specify how much exploration vs. exploitation you want to do, or how much diversity vs. relevance you want to weight. What filters you want to apply. And, what retrievers and models you want to use.

A Simple Example
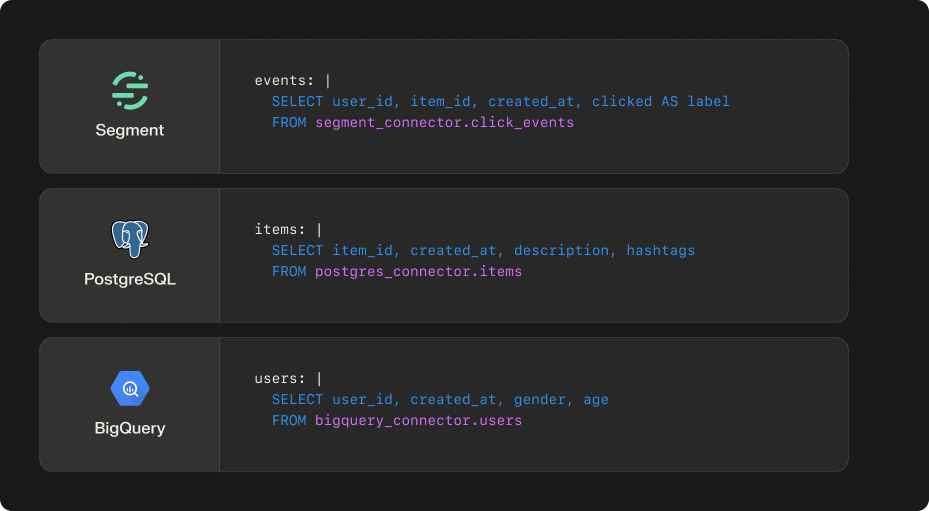
Here's an example of what a model definition file looks like:
model:
name: for_you_feed_v1
description: "Recommend items to show in the for you feed"
pagination_store_ttl: 0 # Seconds.
train_schedule: "@once"
inference_config:
exploration_factor: 0,
diversity_factor: 0,
boosting_factor: 0,
diversity_attributes:
- category_field
retrieval_k: 0
retriever_k_override:
knn: 0,
chronological: 0,
toplist: 0,
trending: 0,
random: 0,
cold_start: 0
limit: 0
connectors:
- id: connector1
name: connector1
type: Dataset
fetch:
events: | ...
users: | ..
items: | ...
global_filters: | ...
personal_filters: | ...
syntax in the fetch section of the model config. Check out the DuckDB SQL Docs.
Under-the-hood Shaped performs SQL syntax tree parsing to ensure these queries are performant on the underlying source. If you do end up running into performance issues with our DuckDB transform layer, some connectors also provide native queries that can be used to limit the data that's fetched.
Model Config [SDK]
| Field | Description |
|---|---|
| name | Assigns a name to your model. It's common to describe the use case and append a version to help with development. |
| description | Describes your model. |
| pagination_store_ttl | Shaped handles the pagination of results for you by adding all served item ids to a 'pagination store' and then filtering out these items from the candidate item set of subsequent requests. The pagination_store_ttl configures the seconds we keep items in the pagination_store for. Speak to your Solution Engineer to find the optimal value for your use case. |
| train_schedule | Shaped enables continuous retrains of your model on a recurring cadence. By default, all models are trained once. For production use cases, we recommend a daily schedule to ensure your model is always up to date. Speak to your Solution Engineer if you need a more frequent train schedule than daily. |
| inference_config | Customizations you can make specific to how the backend ranks your results at inference time. More explanation can be found under Inference Config. |
Inference Config
| Field | Description |
|---|---|
| exploration_factor | Rate of exploration vs. exploitation (between 0.0 and 1.0), used in our bandit algorithms. |
| diversity_factor | How much to weight diversity vs. relevance (between 0.0 and 1.0). This is used in the Maximal Marginal Relevance reorderer. |
| boosting_factor | Probability of a boosted item at each item position (between 0.0 and 1.0), where a "boosted item" is defined more in depth here. |
| diversity_attributes | String list of attributes to consider for diversity reordering. If left empty, defaults to allowing all attributes to be used for diversity reordering. |
| retrieval_k | Number of items retrieved by the model. |
| retriever_k_override | Config specifying the number of items to retrieve split by the type of retriever (KNN, chronological, toplist, trending, random, cold start). |
| limit | The number of items to return in the response. |
Connectors
Add the datasets created in the previous step to the connectors section of your model config.
connectors:
- id: likes
name: likes
type: Dataset
- id: impressions
name: impressions
type: Dataset
- id: reported_posts
name: reported_posts
type: Dataset
- id: users
name: users
type: Dataset
- id: user_favourite_categories
name: user_favourite_categories
type: Dataset
- id: items
name: items
type: Dataset
- id: items_categories
name: items_categories
type: Dataset
Fetch Feature Data
Events
Events must include user_id, item_id, created_at, event_value, and label.
event_value: Describes the event and is useful for analysis.label: Numerical values where anything greater than 0 is positive, and 0 or less is negative. This helps in weighting the events.
For simplicity, you might start with a binary label system.
events: |
SELECT
user_id,
item_id,
created_at,
1 as label,
'like' as event_value
FROM likes
UNION ALL
SELECT
user_id,
item_id,
created_at,
0 as label,
'impression' as event_value
FROM impressions
UNION ALL
SELECT
user_id,
item_id,
created_at,
0 as label,
'reported_post' as event_value
FROM reported_posts
Users and Items
In the users and items sections, include all the users and items on your platform along with attributes that will help the model understand draw connections between them.
users: |
SELECT
user_id,
created_at,
country,
occupation,
gender
FROM users
items: |
SELECT
i.item_id,
i.created_at,
i.price,
i.deleted,
i.public,
ARRAY_AGG(DISTINCT ic.category) AS categories
FROM items i
LEFT JOIN items_categories ic on ic.item_id = i.item_id
WHERE
i.deleted = false
AND i.public = true
Global Filters (Optional)
The global filters define the items that should be filtered out for all users. For example, you may want your rankings to guarantee that all of the following items are filtered out:
- Products that are out of stock
- Certain categories
- Older items
The global filter requires only an item_id column. Say you wanted to exclude a certain
category for all users:
global_filters: |
SELECT
item_id
FROM items_categories
WHERE
category = 'category_to_exclude'
Personal Filters (Optional)
The personal filters define items that should be filtered out for a specific user. For example, you may want your model to:
- Filter out all videos a user has watched before
- Remove posts from blocked and muted users
- Remove items which are not available in the user's country
The personal filter must output a view containing user_id and item_id pairs to be
filtered out. Specifically, if there is a user_id, item_id row, then that user_id will
never be shown that item_id.
If you wanted filter any items a user has seen before:
personal_filters: |
SELECT
user_id,
item_id
FROM impressions
Creating Your Model With The Shaped CLI
Putting it all together, we get the following complete model config and can now use the Shaped CLI to create your model.
model:
name: for_you_feed_v1
description: "Recommend items to show in the for you feed"
pagination_store_ttl: 0 # Seconds.
connectors:
- id: likes
name: likes
type: Dataset
- id: impressions
name: impressions
type: Dataset
- id: reported_posts
name: reported_posts
type: Dataset
- id: users
name: users
type: Dataset
- id: user_favourite_categories
name: user_favourite_categories
type: Dataset
- id: items
name: items
type: Dataset
- id: items_categories
name: items_categories
type: Dataset
fetch:
events: |
SELECT
user_id,
item_id,
created_at,
1 as label,
'like' as event_value
FROM likes
UNION ALL
SELECT
user_id,
item_id,
created_at,
0 as label,
'impression' as event_value
FROM impressions
UNION ALL
SELECT
user_id,
item_id,
created_at,
0 as label,
'reported_post' as event_value
FROM reported_posts
users: |
SELECT
user_id,
created_at,
country,
occupation,
gender
FROM users
items: |
SELECT
i.item_id,
i.created_at,
i.price,
i.deleted,
i.public,
ARRAY_AGG(DISTINCT ic.category) AS categories
FROM items i
LEFT JOIN items_categories ic on ic.item_id = i.item_id
WHERE
i.deleted = false
AND i.public = true
global_filters: |
SELECT
item_id
FROM items_categories
WHERE
category = 'category_to_exclude'
personal_filters: |
SELECT
user_id,
item_id
FROM impressions
Use the Shaped CLI to create your model:
shaped create-model --file model_config.yaml
You'll be able to see your model build on the Shaped Dashboard.