What is Shaped?
Shaped is a platform for recommendations, search and discovery. We help your users find what they're looking for by surfacing the products or content that are most relevant to them. We do this whilst taking into account your business objectives to ensure all sides of your platform or marketplace are being optimized fairly. Under the hood, Shaped is a real-time, 4-stage, recommendation system containing all the data and machine-learning infrastructure needed to understand your data and serve your discovery use-case at scale.
Here's how it works.
1. Connect your data stack
Shaped securely connects directly to your database, data warehouse or analytics applications to ingest your data without having to setup tedious logging infrastructure.

Segment

Amplitude

BigQuery

PostgreSQL

MySQL

Snowflake

Redshift

S3

Google Analytics

MixPanel

Firestore

Kinesis
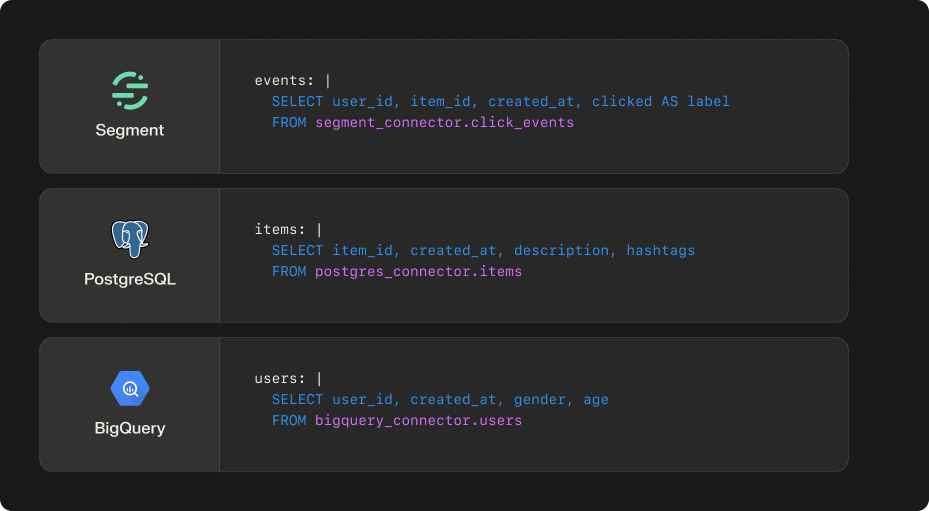
2. Select your data
Once connected, Shaped ingests your users, items and events to train and build your recommendation system.
- Your events contains the interactions that relate your users and items together. These contain the behavioral information necessary to learn what types of users like what types of items. Furthermore, they indicate the interaction objective that’s being optimized. For example, if you specify the interaction type as “clicks”, the ranking model will learn which users are most likely to click which content.
Typically in recommendation systems you optimize auxiliary objectives (e.g “clicks”, “add-to-cart”) with the hopes that it will correlate with the final business metric (e.g daily-active users or revenue). You have the freedom to explore different interaction types that you expect will lead to an improvement in the final business metrics.
The items are what you want to be surfaced to your users. For a product like TikTok, this could be the videos within the feed. For a marketplace like Airbnb, this could be the listings displayed to each user. We use the attributes of the items to determine content similarity allowing us to recommend relevant items without many interactions.
The users are the identities you're personalizing for. Much like the items data we use the user attribute data to understand user similarity when we don't have much interaction data, this is particularly helpful for new (cold-start) users.
3. Model training & deployment
Once ingested, Shaped can begin training your bespoke recommendation model. We look at the schema, format and volume of your data types to determine the set of recommendation models that are best for your use-case. We then perform cross-validation on a held-out test set to choose the best subset of models for your evaluation metrics. The final set of models are A/B tested and evaluated online to ensure that only the model with the highest uplift is served to your users.
Although Shaped's documentation mostly references one recommendation model, in practice we use several models to provide your ranked results. We use content understanding models to automatically encode features from your data types, models to retrieve initial item candidates, models to score the affinity between users and items and models to reorder your ranking and optimize your secondary objectives (e.g. diversity of recommendations).

4. Fetch rankings
After a few hours your data will have been ingested, your models will have been trained and your recommendation system will have been deployed. Shaped can now be used to retrieve rankings for any of your users. We provide several ranking APIs that integrate directly into your product to support your real-time discovery use-case.
shaped rank --model_name video_recommendations --user_id "XA123F2"
{
"ids":[
"427010",
"182094",
...
],
"scores":[
0.919,
0.832,
...
],
"metadata": [
{
"title": "CatVideo1",
"hashtags": ["animals", "funny"]
},
{
"title": "PuppyVideo2",
"hashtags": ["cuteness", "animals"]
},
...
]
}
5. Continuous training and on-going improvements
After deploying your model Shaped will continue to improve your recommendation system over time. Using the data connections, data will be continuously ingested to ensure we have the most up-to-date user, item, and event data. This data is used to retrain your recommendation models to pick up any data distribution shift (i.e., a recent trends in your data). Shaped uses the feedback from the subsequent events after deployment to continually adjust your models configurations and weights.