This is an article from the Shaped 1.0 documentation. The APIs have changed and information may be outdated. Go to Shaped 2.0 docs
Architecture
Shaped simplifies the complexity of building and deploying recommendation systems, but under the hood lies a sophisticated ecosystem of models working in concert to deliver exceptional results.
Shaped provides three primary interfaces:
- Dataset API
Connect your data sources and manage datasets for training and inference. - Transform API
Transform, enrich, clean and tag your datasets for use in any of your models. - Model API
Configure, train, and manage your recommendation and search models. - Rank API
Retrieve personalized rankings, similar items, and other recommendations in real time.
Once a model is created, Shaped provisions several stream and batch data pipelines to continuously process your data and manage your model deployments.
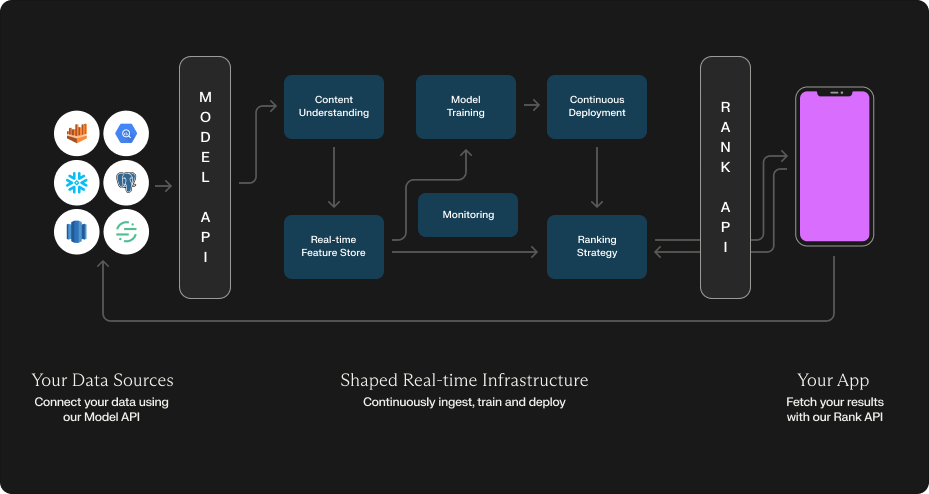
1. Content Understanding: Transforming Raw Data into Meaningful Representations
Before any recommendations can be made, Shaped analyzes your raw data and generates rich embeddings that capture the underlying meaning and relationships. These embeddings are used as input to downstream retrieval and ranking models.
2. Feature Store
Shaped ingests your data into a real-time feature store, enabling efficient serving of features at both training and inference time.
3. Machine-Learning Training
Shaped trains and evaluates a subset of recommendation system architectures tailored to your use case. The best-performing models are deployed to production.
4. Continuous Deployment
Embeddings generated by content and ranking models are indexed in a vector store and deployed to real-time endpoints.
5. Ranking Strategy
When a rank request is made, Shaped employs various ranking strategies using online feature stores, vector stores, and an ensemble of models to deliver the final results.
6. Continuous Feedback
Shaped continuously trains and improves your recommendation system by attributing interactions from your connected data sources to the models.
7. Monitoring
Robust monitoring and alerting ensure data quality, machine learning accuracy, and performance regressions are surfaced quickly.
Shaped is a 4 Stage Ranking System
Shaped is built as a 4-stage ranking system, a typical architecture for state-of-the-art recommendation and search systems. Here's how it works:
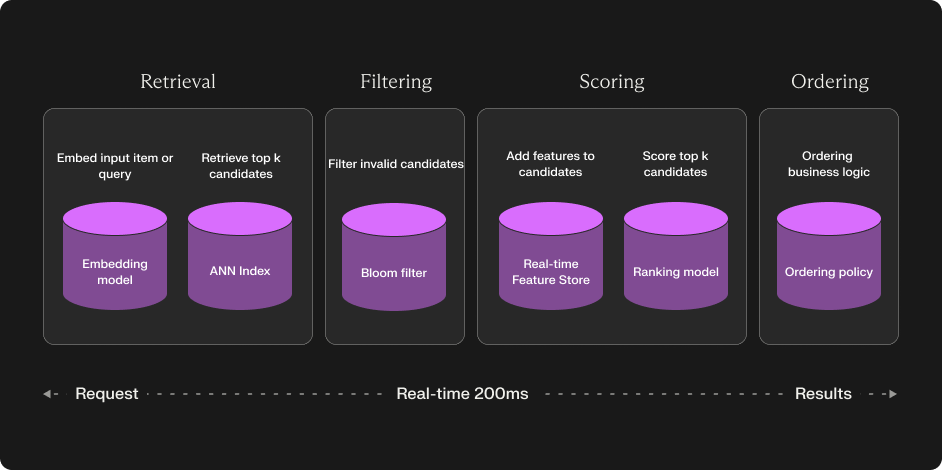
1. Candidate Retrieval
A high-recall step that retrieves all candidate items for ranking. Shaped uses methods like collaborative filtering, embedding-based retrieval, and hybrid strategies to ensure relevant candidates are surfaced.
Shaped employs a diverse set of retrieval models to efficiently surface the most promising items:
- Embedding-Based Retrieval:
- Two-Tower Neural Networks, Matrix Factorization, Word2Vec, and more.
- Traditional Methods:
- BM25, N-gram models, and chronological or trending retrieval.
- Hybrid Strategies:
- Combine collaborative filtering with content-based filtering for optimal results.
- Approximate Nearest Neighbor (ANN) Search:
- Libraries like Faiss and HNSWlib for speed and scalability.
2. Candidate Filtering
Filters out items that don’t meet specific criteria (e.g., already viewed items or out-of-stock inventory). This step is performed at rank time.
There's four primary ways Shaped helps with filtering:
- Global filter: this provides a way to filter out any item in real-time. This is useful for stock that isn't available.
- Personal filter: this is a filter that's built for each specific user. It's useful for filtering out seen items or similar.
- Facet filtering: this is a filter predicate syntax that allows you to filter out a retrieved list of items in a custom way.
- Pagination filtering: this is a filter that's used for subsequent requests to filter out items that have already been shown to the user immediately. This is useful for pagination.
3. Scoring
A scoring model predicts the likelihood of user interaction with each item. Shaped employs deep learning models like DeepFM, Wide & Deep, and transformer-based models for accurate scoring.
Shaped’s scoring models estimate the likelihood of user engagement with each item:
- Deep Learning Models:
- DeepFM, Wide & Deep, and transformer-based models.
- Traditional Machine Learning:
- Gradient Boosted Trees, Factorization Machines, and more.
4. Ordering
The final ranked results are sorted based on scores, with optional exploration techniques (e.g., bandit algorithms) to balance relevance and discovery.
Shaped optimizes the final order of recommendations, balancing relevance with discovery:
- Bandit Algorithms: Learn from user feedback to balance exploration and exploitation.
- Maximal Marginal Relevance (MMR): Ensures a mix of relevance and diversity.
Shaped continuously evaluates different model policy combinations to ensure the highest uplift for your use case.