Shaped Architecture
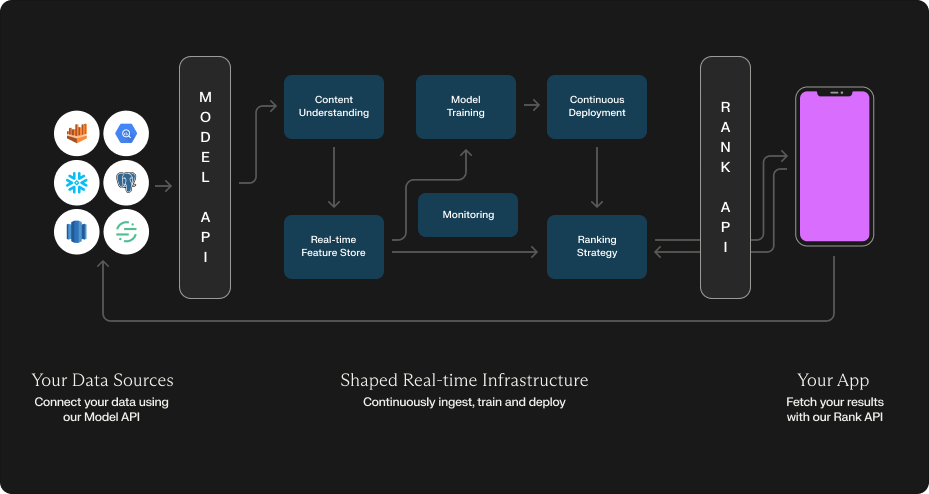
High level overview
Shaped provides two primary interfaces:
The Model API is used to setup your data connections and model configurations and create your recommendation system. Once a model is created, we provision several stream and batch data pipelines to continuously process your data and manage your model deployments. Notably:
Content understanding: When user and item data is ingested we encode it using state-of-the-art tabular, language, image and video encoders. This feature encoding is what's used as input to your down-stream retrieval and ranking models.
Feature Store: We ingest your data into a real-time feature store that can be used for efficient serving of features at train and inference time.
Machine-Learning Training: We train and evaluate a subset of recommendation system architectures for your use-case and choose a set of best ones to deploy to your users.
Continuous Deployment: We take the various embeddings generated by your machine-learning models (both content and ranking models), index them in our vector store and deploy the models to a real-time endpoint.
Ranking Strategy: When a rank request is made to the Rank API, we provide several different ranking strategies based on the input that you provide. These strategies use the online-feature stores, online-vector stores and ensemble of online models to provide your final results.
Continuous Feedback: We attribute interactions found within your connected data sources to Shaped's models and continuously train and improve your recommendation system based on counterfactual results.
Monitoring: We have robust monitoring and alerting to ensure data quality, machine learning accuracy and performance regressions are surfaced quickly.
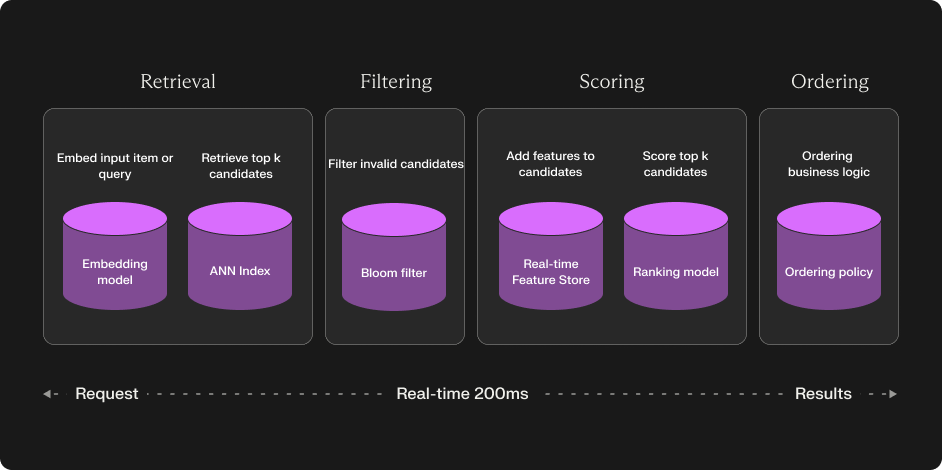
Configurable 4 stage recommendation system
Shaped is built as a 4-stage recommendation system — a typical architecture used to build state-of-the-art recommendation systems in industry. At a high level when a rank request is retrieve the following steps are executed:
Candidate retrieval — A high recall step that retrieves all candidate items that need to be ranked for a user. In one of our recommendation model policies we perform this offline, using a light-weight collaborative filtering model that finds similarity between users and items from just the interactions.
Candidate filtering — This step filters out any last minute items from the candidate set (e.g. if the user has already viewed the item or if inventory was recently set to zero). We perform this at rank-time.
Scoring — A scoring model then decides the confidence that each user will interact with the item. In one of our model policies this takes into consideration the context of the user and item to provide better scores than at the retrieval steps.
Ordering — The final ranked results are then sorted based on the sorted scoring order. Some indeterminism is added into the final ranking (e.g. placing random candidate items towards the top of the rankings) to avoid filter bubbles that bias the ranking algorithm.
Shaped provides many different model policies at ranking strategies that handle each of these steps in different ways. We continuously evaluate different model policy combinations for your data and use-case to ensure we're guaranteeing the highest uplift.
Built for the Modern Data Stack
Most of the difficulty in getting started with productionizing machine-learning isn't the modeling or machine-learning infrastructure but, instead, the data pipelines and processing needed for an up-to-date understanding of your users, items and analytics. To handle this problem, we've built Shaped directly on-top of your data stack so that you can get started without having to build these data pipelines yourself.
You can connect Shaped directly to your:
- Data warehouse (e.g. BigQuery, Snowflake, Redshift)
- Database (e.g. MySQL, Postgres)
- Blob storage (e.g. S3, GCS)
- Analytics applications (e.g. Segment, Amplitude)
Once a model connector is setup, we provision either batch or stream data pipelines to ingest the data into our real-time feature store. Our stream pipelines can understand and react to your platform's data within 30 seconds. Our batch pipelines ingest data at a longer frequency, typically 4 hours.
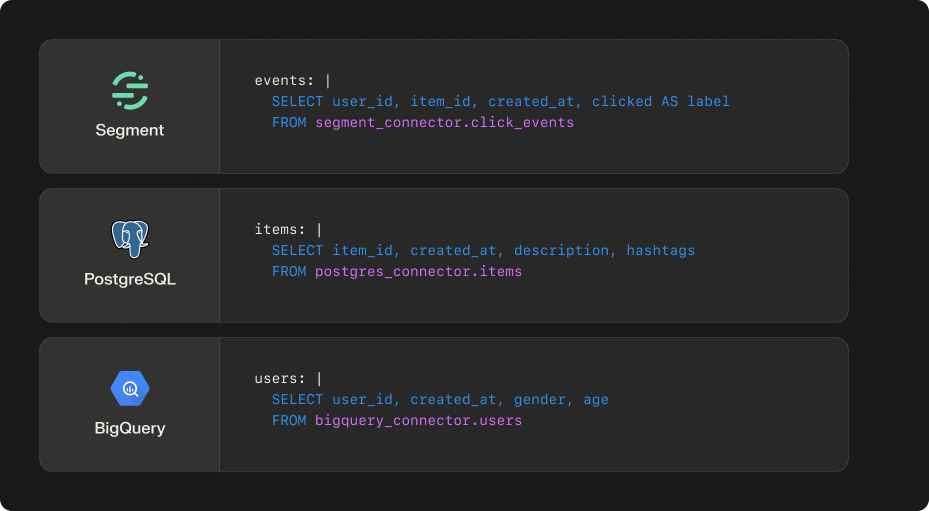
Declarative SQL model creation
To assist with the transformations needed to get your custom source data into the format we need for ranking, Shaped provides a SQL interface for selecting the specific data for each model. This unified SQL interface makes it easy to build new models with different combinations of data quickly. It means that you don't need to spend time getting all the data cleaned and materialized before using Shaped, you can simply do these transforms using our pipelines. Finally, you can apply SQL based transforms on the data-sources that don't traditionally support SQL. E.g. on your blog storage or analytics application data.
The interface uses DuckDB SQL that has been extended to include all connector sources that are provided within the model creation schema. Under-the-hood we do SQL syntax tree parsing to ensure these queries are performant on the underlying source. If you do end up running into performance issues with our DuckDB transform layer, some connectors also provide native queries that can be used to limit the data that's fetched.

Real-time AI
From ingestion to inference, Shaped was built with the future of real-time infrastructure in mind. Our streaming pipelines and online-feature store can ingest and store your users, items and events within 30 seconds, making them available at inference time almost immediately. Our ranking strategies use this real-time data to adjust what's being ranked by taking into account real-time signal like the users session interactions, recent global trends of data (e.g. some piece of particularly news worthy information such as the result of a soccer game), and update critical user or item feature attributes (e.g. item inventory for a marketplace).
This real-time reranking is what makes applications like TikTok or Instagram feel like they're reacting to your every interaction, personalizing based on your intent in the specific moment. Session based recommendations like this is also helpful for anonymous or cold-start users that have no previous interaction history; sometimes the session context is the only thing you can personalize around!

Optimize for all sides of your data
For most recommendation use-cases there's typically more than just one objective you're optimizing for. Yes, you'll likely have a key engagement objective (like 'clicks') or conversion objective (like 'purchases') that you'd like to maximize, however, what other objectives will you have? Maybe you'll also want to optimize the diversity of content clicks or the cart size of purchases. Furthermore, maybe you'll want to optimize differently for different stake-holders within your use-case. For a marketplace you may want to optimize for both the buyers and the sellers in a fair way.
We distill this multi-objective optimization problem into two parts:
- Top-level metrics (e.g. accuracy, diversity, novelty, serendipity)
- User, item or event slices (e.g. creators, consumers, sellers, buyers, new items, old items, purchases)
Shaped takes into consideration several different top-level metrics and data optimization slices combinations when optimizing your recommendation system. This ensures that different cohorts of users, item taxonomies or event types have a fairly weighted trade-off when being trained to optimize your recommendations.
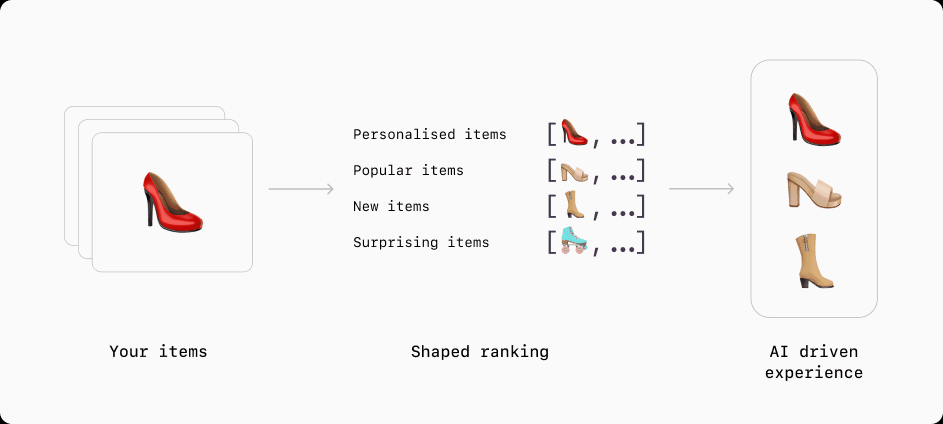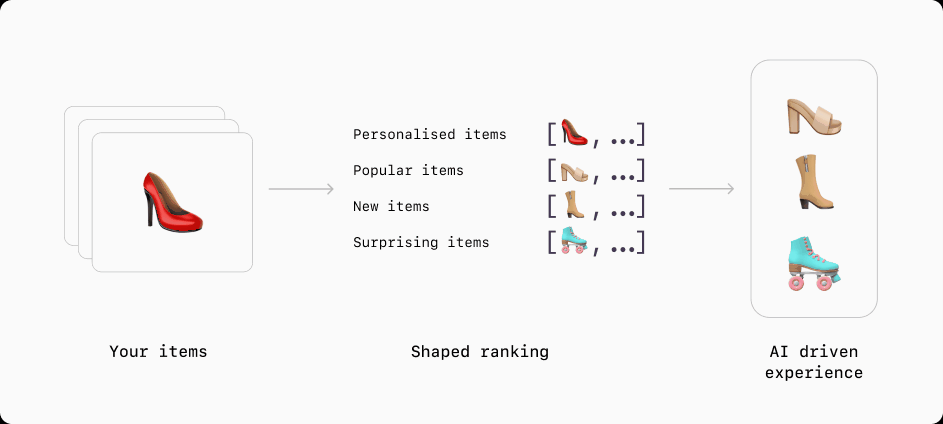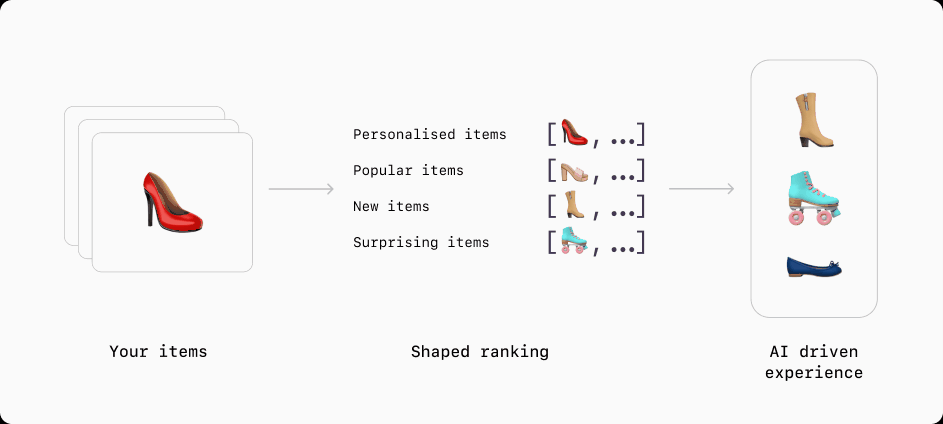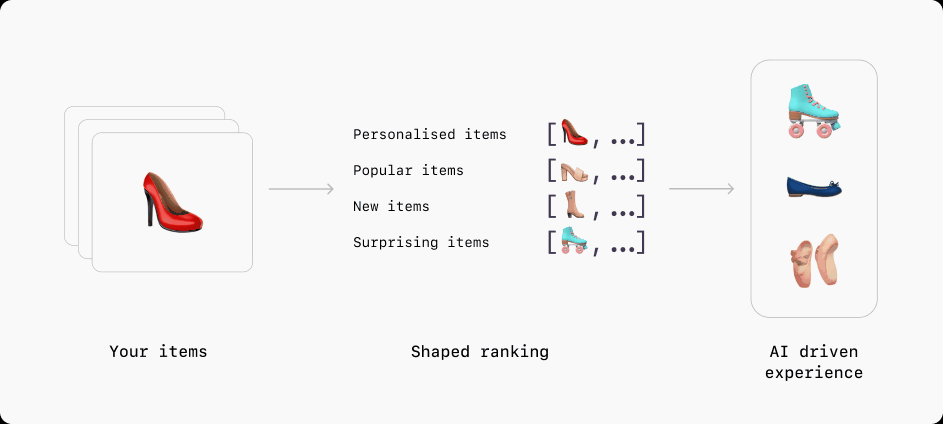
Understand any data type
To get the most from your data, modern recommendation and ranking methods need all the data they can get. As well as understanding traditional tabular data types such as categorical (enums) and numerical (scalars) variables, Shaped understands complex data types like image, audio, language and video. It does this by processing these data types into embeddings using pre-trained understanding models. These embeddings are then fed into the ranking models to improve its understanding of the input and the the performance of the final ranking.
For example, if you are building a social post recommendation model, the content of the post is crucial in understanding the relevance it has to a user. And these embedding models can understand that content. It is even more crucial when you lack interaction data for that post (e.g. say for a newly created post on the platform). Note, this is called the cold-start problem and will be discussed later.
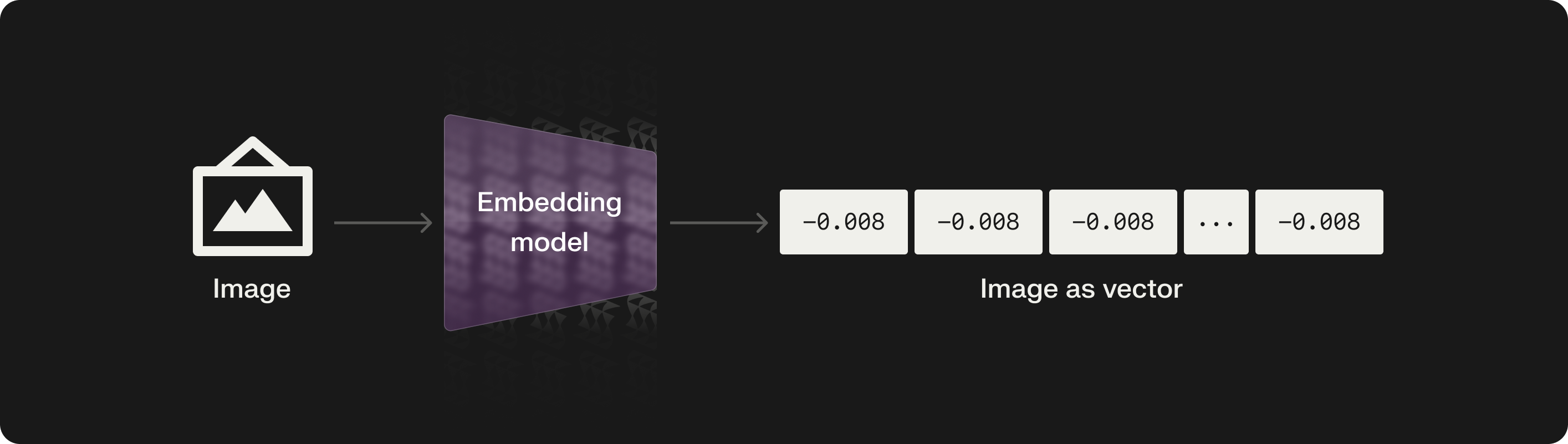
What are embeddings? Embeddings are compressed numerical representations that encapsulate the features of the data.
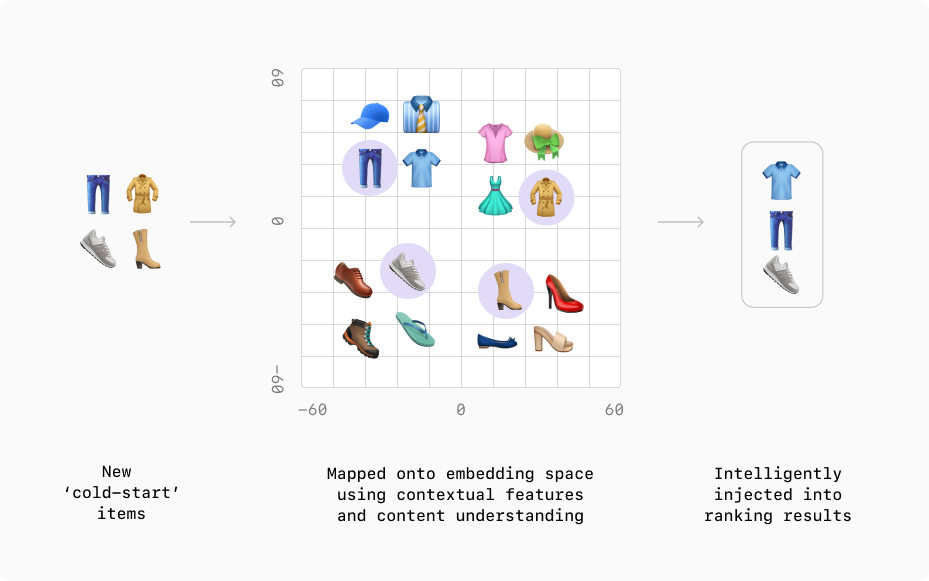
Cold-start problem? No problem
Ranking models learn the relevance between users and items based on the interaction data that relates them together. But what happens when you have a new user or item?
This is called the cold-start problem in recommendation systems. Shaped addresses it in three ways:
Using user and item context features. Having the context allows Shaped to rank results in the same way that similar users or items (that may have more interaction data) would be ranked. For users, these features may be demographic or interest data that is collected at sign-up time. For items, these features may be any metadata, descriptions, or the item content type itself.
Cold-start item optimization. In the ordering step, we intelligently inject cold-start items to give them a chance to be seen by your users. The proportion of low interaction items that we inject can be chosen using the exploration_factor argument within the Create Model API.
Session-based recommendations. Our endpoint accepts the latest user interactions (often called sessions) and uses them to return the most relevant recommendations for the current context. By using the latest user interactions you can ensure you serve recommendations relevant to the most recent user intents. This functionality can be used to serve recommendations to users just introduced to the system.
Robust, reliable and scalable Infrastructure
We're continuously increasing our scale constraints to support larger traffic loads. Please get in touch if you have specific performance or scale constraints that you want to meet.
Shaped’s cloud API supports the following scale limits:
Dimension | Limit |
|---|---|
| Unique users | 100+ million |
| Unique items | 10 million |
| Personal filters | 50 million |
| Requests per month | 36 million |
| Requests per second | 1000 |
| Train frequency | 4 hours |
| Event and filter ingestion | < 30 seconds |
| User and item catalog ingestion | 10 minute |
Please contact us if you require more constraints.