Product Recommendations (Amazon Product)
In this tutorial we'll show you how to setup a model for the Amazon Product dataset. This dataset contains a large crawl of product reviews data from Amazon.com. With Shaped we'll be able to create a product recommendation model that can predict the most likely products each user will want to buy.
This tutorial will be shown using Shaped's Postgres data connector but you can easily translate to any of the data stores we support.
Let's get started! 🚀
You can follow along in our accompanying notebook!
Dataset Preparation
The complete Amazon dataset contains 82.8 million reviews, 9.35 million products and 20.98 million users.
Although Shaped is built to handle the scale of this data, to reduce processing time for this tutorial we'll only use the subset of 'Beauty' categorized products. This is a subset of 371k reviews that's often used for evaluation in the RecSys literature.
Download public dataset
We can fetch and unarchive the Beauty rating subset and product metadata with the following commands:
# Beauty ratings.
curl -L -O "https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023/resolve/main/raw/review_categories/All_Beauty.jsonl"
# Beauty product metadata.
curl -L -O "https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023/resolve/main/raw/meta_categories/meta_All_Beauty.jsonl"
Using pandas, let's take a look at the downloaded dataset. There are two tables of interest:
- reviews which are stored in All_Beauty.json
- products which are stored in meta_All_Beauty.json Note that the data is actually stored in jsonl files so we need to use lines=True when reading the data.
import pandas as pd
events_df = pd.read_json('All_Beauty.json', lines=True)
products_df = pd.read_json('meta_All_Beauty.json', lines=True)
display(events_df.head())
display(products_df.head())
events_df

products_df
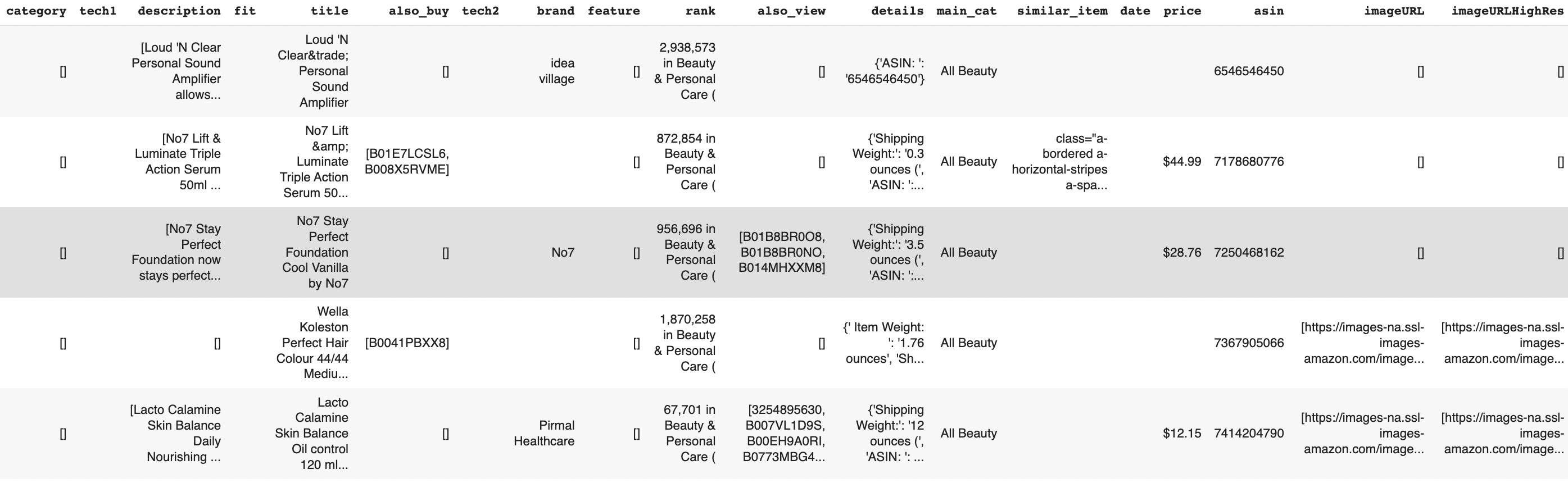
You'll notice that it's fairly noisy. The prices have to be treated as strings because of the '$' sign, and many of the fields contain empty strings or malformed HTML that was misparsed during the crawling process. In most cases, you'd have to spend time cleaning all this data, however, with Shaped you can feed it through and Shaped will do the cleaning for you. The way we do this is by treating all input data as unstructured, and using large language models to distill the meaning of each column.
Shaped doesn't require much data to work. At a minimum we need to know the user_id,
item_id, label, and created_at columns of the interactions table. If the users
and items tables are provided then the only requirement is their respective id columns
are aliased to user_id and item_id.
For brevity, we'll only use a subset of the columns. You'll notice we include a couple of feature columns for the items (title and price).
For the interaction data we take a look at events_df and see the relevant columns
for the interactions are:
- reviewerID: Is the user who is reviewing the item.
- asin: Is a unique identification for a product. It will be used as an item to train our models.
- overall: Is the review of an product given by a user.
- unixReviewTime: Is the review of an product given by a user.
For the item data we take a look at products_df and see the relevant columns for the
items are:
- asin: Is a unique identification for a product.
- title: Name of the product.
- price: Price in US dollars.
- brand: The product's brand.
Note that we could use more columns like the description but we're just choosing a subset for brevity.
As next steps we'll show you how you can setup the Shaped CLI, sync the data to Shaped and create a product recommendation model.
Shaped CLI Setup
Installing the Shaped CLI
You'll need to install the Shaped CLI if you haven't already. You can do this with the following command:
pip install shaped
Shaped supports Python 3.8+, take a look at the installation instructions if you need to install pip.
Initialize the CLI
You can then initialize the shaped client with your API key. If you don't have an API key yet, check out the 'How to get an API key' page.
shaped init --api-key <YOUR_API_KEY>
Create your Shaped datasets
To sync the dataset to Shaped you need to create Shaped datasets for both the ratings
data and the product metadata. We have a convenience function called create-dataset-from-uri
that helps you create these datasets directly from local or S3 uris.
shaped create-dataset-from-uri --name amazon_beauty_ratings --type json --path ./All_Beauty.json
shaped create-dataset-from-uri --name amazon_beauty_products --type json --path ./meta_All_Beauty.json
Create your Shaped model
We're now ready to create your Shaped model! The following command sets up a simple model using the ratings event data and product metadata we just synced to Shaped:
---
model:
name: amazon_beauty_product_recommendations
interaction_expiration_days: 22000
connectors:
- type: Dataset
name: amazon_beauty_products
id: amazon_beauty_products
- type: Dataset
name: amazon_beauty_ratings
id: amazon_beauty_ratings
fetch:
events: |
SELECT
CASE
WHEN overall >= 4 THEN 1
ELSE 0
END as label,
asin AS item_id,
reviewerID AS user_id,
unixReviewTime AS created_at,
summary,
verified,
FROM amazon_beauty_ratings
items: |
SELECT
asin AS item_id,
title,
TRY_CAST(TRIM(price, '$') AS DOUBLE) AS price,
brand,
FROM amazon_beauty_products
shaped create-model --file amazon_beauty_product_recommendation.yaml
Inspect your model
Your recommendation model can take up to a few hours to setup and historic data training. This time mostly depends on how large your dataset is i.e. the volume of your users, items and interactions and the number of attributes you're providing.
While the model is being setup, you can view it's status with either the 'List Models' or 'View Model' endpoints. For example, with the CLI:
shaped list-models
Response:
[
"models": {
"created_at": "2024-01-18T19:17:51 UTC",
"model_name": "amazon_beauty_product_recommendation",
"model_uri": "https://api.shaped.ai/v1/models/amazon_beauty_product_recommendation",
"status": "FETCHING",
}
]
As you see the model is currently fetching the data. The initial model creation pipeline goes through the following stages in order:
SCHEDULINGFETCHINGTRAININGTUNINGDEPLOYINGACTIVE
You can periodically poll Shaped to inspect these status changes. Once it's in the
ACTIVE state, you can move to next step and use it to make rank requests.
Fetch your recommendations
You're now ready to fetch your movie recommendations. You can do this with the
Rank endpoint,
just provide the user_id you wish to get the recommendations for and the number of
recommendations you want returned.
Shaped's CLI provides a convenience rank command to quickly retrieve results from the command line. You can use it as follows:
shaped rank --model-name amazon_beauty_product_recommendation --user-id 'AHGHQ5SPYZ60Q' --limit 5
Response:
{
"ids":[
"0002007770",
"000100039X",
"0002051850",
"0002219417",
"0000031887",
],
"scores":[
0.98,
0.92,
0.73,
0.69,
0.68
],
"metadata": [
{
"title": "Compact Hair Dryer",
"price": "64.99",
},
{
"title": "Eye Balm",
"price": "32.0",
},
{
"title": "Ear and Nose Hair Trimmer",
"price": "12.99",
},
{
"title": "Pure Instinct Perfume",
"price": "16.95",
},
{
"title": "Eye Shadow and Eye Liner Pen",
"price": "15.99",
},
]
}
The response returns 3 parallel arrays containing the ids, ranking scores and item metadata for the movies that Shaped estimates are most interesting to the given user.
If you want to integrate this endpoint into your website or application you can use the Rank POST REST endpoint directly with the following request:
curl https://api.shaped.ai/v1/models/amazon_beauty_product_recommendation/rank \
-H "x-api-key: <API_KEY>" \
-H "Content-Type: application/json"
-d '{
"user_id": "AHGHQ5SPYZ60Q",
"limit": 5,
"return_metadata": true
}'
Clean Up
Don't forget to delete your model once you've finished with it, you can do it with the following CLI command:
shaped delete-model --model-name amazon_beauty_product_recommendation