How it works
This is a preview of the new Shaped docs. Found an issue or have feedback? Let us know!
Shaped is a platform for recommendations, search and discovery. It surfaces products or content based on relevance to users while optimizing for business objectives. Shaped is a real-time, 4-stage recommendation system that includes data ingestion and machine learning infrastructure for training and serving recommendation models at scale.
Here's how it works.
1. Connect your data stack
Shaped connects directly to your database, data warehouse, or analytics applications to ingest data. See all connectors here.

Segment

Amplitude

BigQuery

PostgreSQL

MySQL

Snowflake

Redshift

S3

Google Analytics

MixPanel

Firestore

Kinesis
2. Select & transform your data
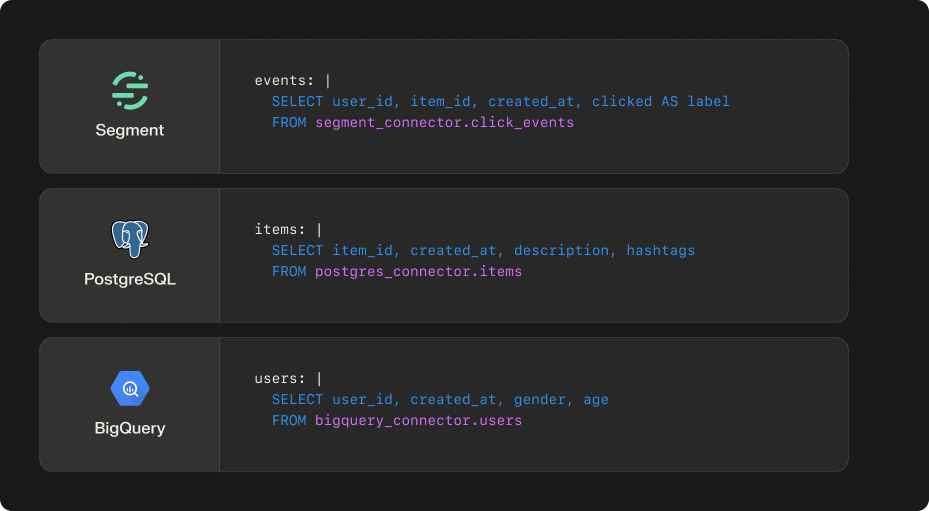
After connecting, Shaped ingests users, items, and events to train recommendation or search models.
- Events represent interactions between users and items. They provide behavioral signals used to learn user-item affinities. The event type defines the optimization objective. For example, if the interaction type is "clicks", the ranking model learns to predict click probability.
Recommendation systems typically optimize auxiliary objectives (e.g., "clicks", "add-to-cart") that correlate with business metrics (e.g., daily-active users or revenue). You can configure different interaction types based on expected impact on business metrics.
Items are the entities to be surfaced to users (e.g., videos in a feed, listings in a marketplace). Item attributes are used to compute content similarity, enabling recommendations for items with limited interaction history.
Users are the identities being personalized. User attributes are used to compute user similarity when interaction data is sparse, which helps with cold-start users.
Transform your data
Use Shaped Transforms to mutate or enrich data. For example, create a SQL transform to join tables (e.g., creator and post tables) that materializes at insert time. You can also use transforms to enrich data with LLMs for improved search, recommendations, and analytics.
3. Model training & deployment
After ingestion, Shaped trains recommendation models. Model selection is based on schema, format, and volume of your data types. Cross-validation on a held-out test set selects the best subset of models for your evaluation metrics. Selected models are A/B tested online, and the model with the highest performance uplift is deployed.
Shaped uses multiple models to generate ranked results: content understanding models for feature encoding, retrieval models for candidate generation, scoring models for user-item affinity, and re-ranking models to optimize secondary objectives (e.g., diversity).

4. Fetch rankings
After ingestion and training (typically a few hours), the recommendation system is deployed. Use the ranking APIs and SDKs to retrieve rankings for users in real-time.
- CLI
- JavaScript
- Python
shaped rank --model-name your_model_name --user-id "your_users"
const {rank} = require("@shaped.ai/client").Client('your_api_key')
// Get item recommendations for a user.
recommendations = rank({
model_name: "your_model_name",
user_id: "your_users",
})
from shaped import ShapedClient
client = ShapedClient(api_key="your_api_key")
# Get item recommendations for a user.
recommendations = client.rank(
model_name="your_model_name",
user_id="your_users",
)
{
"ids":[
"427010",
"182094",
...
],
"scores":[
0.919,
0.832,
...
],
"metadata": [
{
"title": "CatVideo1",
"hashtags": ["animals", "funny"]
},
{
"title": "PuppyVideo2",
"hashtags": ["cuteness", "animals"]
},
...
]
}
5. Continuous training and on-going improvements
After deployment, Shaped continuously retrains models using newly ingested data from your data connections. Retraining captures data distribution shifts and recent trends. Post-deployment event feedback is used to adjust model configurations and weights.